Not Just a Designer: Code First in Entity Framework
Code First is a new development approach in the Entity Framework stack that can simplify the understanding and maintenance of your domain model.
In the middle of 2008, Microsoft published the first version of the Entity Framework (Entity Framework 1) as part of Visual Studio 2008 SP1. The Entity Framework was created as an object-relational mapping (OR/M) tool that helps create an abstraction layer on top of ADO.NET namespaces. When it first shipped, the Entity Framework supplied two development approaches out of the box: the Database First approach and the Model First approach.
In the Database First approach, you started with an existing database and used the Entity Framework wizard to create the Entity Data Model (EDM). The model was built as a one-to-one mapping between the database and the conceptual model, and after it was created you could customize it to make it more like the domain requirements.
On the other hand, the Model First approach was limited in the first version. When Visual Studio 2010 and the Microsoft .NET Framework 4 were shipped, the Model First implementation was improved significantly. In Model First, you could start working with an empty model and create your desired conceptual model. After the creation of the model, you could use the Generate Database Script from Model feature, which wasn't part of the Entity Framework 1 designer, to create the EDM storage and mapping schemas and also to generate a Data Definition Language (DDL) script. The generated DDL script could be used to create a database that would fit to the model according to a Model First workflow.
In the Entity Framework 1, the creation of the store schema definition language (SSDL), mapping specification language (MSL) and the script weren't available, so you needed to handcraft them, as well as create the database. Both of the approaches gave you a lot of flexibility while you built EDMs and could be used by the Entity Framework Designer. But they both forced you to use the designer and an .edmx file to create the EDM more easily.
The new Entity Framework Code First feature can help you use a more domain-driven approach while building your data tier on top of the Entity Framework. Microsoft said it expected to deliver the new functionality before the end of April 2011 -- so it should be available by the time you read this. In Code First, you can use only code without any designer or .edmx files to create the domain model. First you create Plain Old C# Object (POCO) classes that represent the domain model, and then you use a set of built-in tools like a fluent interface, data annotations and conventions in order to configure a runtime EDM for the domain model. Figure 1 summarizes the current Entity Framework development approaches.

[Click on image for larger view.] |
| Figure 1. Entity Framework development approaches. |
This article will explain what the Code First development approach is all about and how to use it in order to implement your data-access layer. The article is based on the Entity Framework Feature community technology preview (CTP) 5, therefore things might change in the official release of Code First.
Let It Be Code
Code First was developed on top of Entity Framework 4 functionality as a stand-alone package. The idea behind it is to supply a simple API for an EDM runtime configuration, providing a second alternative to using .edmx files. The rationale behind the feature is that many developers, including myself, prefer to write code and use conventions instead of using XML files for configurations and modeling. It's faster, more productive, simpler and, of course, less error-prone than a hardcoded static-configuration file. This is why this approach is so essential in the development of a tool like the Entity Framework.
Another driver is domain-driven development principals. Using Code First enables the creation of a domain model without any concern about the persistence layer and how it's going to be implemented.
All you need to do is develop your domain model using POCO classes and let Code First figure out how to create the EDM from it (and even the database in some circumstances). This is implemented by a conventions engine that's built inside the Code First runtime. If you want to change Code First default conventions, there are a lot of extension points in the configuration process, such as a fluent interface API, data annotations and more.
DbContext and DbSet Classes
When starting to develop with Code First, you'll first encounter the new DbContext and DbSet classes. These classes represent a lightweight wrapper implementation on top of the Entity Framework ObjectContext and ObjectSet classes, respectively. You use the DbContext and DbSet classes as you used the ObjectContext and ObjectSet classes, but with less exposed Entity Framework API noise.
Also, there are some new methods that help implement common development needs, such as finding an entity or changing an entity state. If you aren't familiar with ObjectContext and ObjectSet, I suggest you to go to the following MSDN Library pages before you go on with the article:
tinyurl.com/6bsoera and
tinyurl.com/6988f55.
The DbContext is a main object in Code First that exposes the interaction between the Entity Framework and the database. Its responsibilities include database connectivity, change tracking, data persistence, entities caching and more. It's also a container of all the DbSets that you'll create in order to work against the database.
The DbSet is a collection representation of a set of entities. You can think about it as an in-memory representation of database records, but it's much more than that. It exposes a set of collection methods such as Add and Remove in order to manipulate the set's data. It also enables you to use LINQ to Entities to query its data.
The Domain ModelThe first thing I encourage developers to do when they start using Code First is build their domain model. In order to build a domain model you need to build simple POCO classes and a database context that inherit from DbContext. You'll need to add a reference to the EntityFramework assembly, which is installed with the Entity Framework Feature CTP. In
Listing 1 you can take a look at the model that I'm using here.
Listing 1 shows a simple model that includes companies and their associated employees. The interesting thing is the CompanyEntities, which is the context to the database. The context is playing the role as the database gateway, which will help to manage the entities' state, open connections and more. It includes two DbSets for each entity set that we have in the model. The entities will be placed in an entities assembly while the context will be placed in the Data Access Layer.
Using only this model is enough to get a runtime EDM. Code First will use its default conventions in order to achieve the building of the EDM during the execution of the application. These conventions include building primary keys out of properties that have the Id suffix, building foreign keys out of entities relations and more. Also, as a side effect, if a database or a connection string to an existing database doesn't exist, the Code First runtime will create a database in the SQL Express server of the current machine.
The calling to the constructor of DbContext with a string parameter, as in
Listing 1, will force Code First to look at whether a connection string with the Manpower name exists. If the connection string exists then it will be used as a connection string to the database; otherwise the supplied string will be used as the database name. If the developer doesn't supply a database name, the convention of the database name is the namespace of the assembly followed by the name of the context (for example, DAL.CompanyEntities). Figure 2 shows the created database after running the model inside a simple console application.
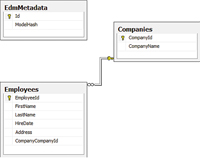
[Click on image for larger view.] |
| Figure 2. The generated database. |
As you can see, the database was created with all the relevant primary keys and foreign keys. Also, an EdmMetadata table was generated. This table is used by the DbContext in order to check whether the database schema matches the current model. Up until now I've done nothing to configure the generated runtime EDM. Let's dive into the EDM configurations.
Using DbModelBuilder and Code First Fluent API
One of the options to configure EDMs in Code First is a fluent API that's supplied through a class called DbModelBuilder. The DbModel-Builder role does all the heavy lifting of creating the EDM during runtime. Using the fluent API can help you configure the generated runtime EDM and shape it to your will.
The main way to configure the runtime generated model is by overriding the DbContext OnModelCreating method. The method gets a DbModelBuilder instance as a parameter, which is used to configure the model. The configuration phase occurs only once in the application, and the generated EDM is stored in the application cache.
Listing 2 shows an example of how to write configurations with the fluent API.
First you override the OnModelCreating method in the custom DbContext that you've created. Then, for every aspect you want, you configure the DbModelBuilder using the fluent API. You first choose which element to configure: an entity or a complex type. The example shows how to configure entities by using the Entity generic method. The Entity method indicates on which entity to add the configurations while the ComplexType does the same for complex types.
